
Как расширить семантическое ядро
Основной источник семантики — это Яндекс.Вордстат (wordstat.yandex.ru)
Запросы, собираемые через этот инструмент актуальны и для поисковой системы Google.
Вариантов расширения ядра множество, в том числе, можно это делать вручную через интерфейс вордстата, ниже описан основной сценарий с помощью Инструмента Частотность.
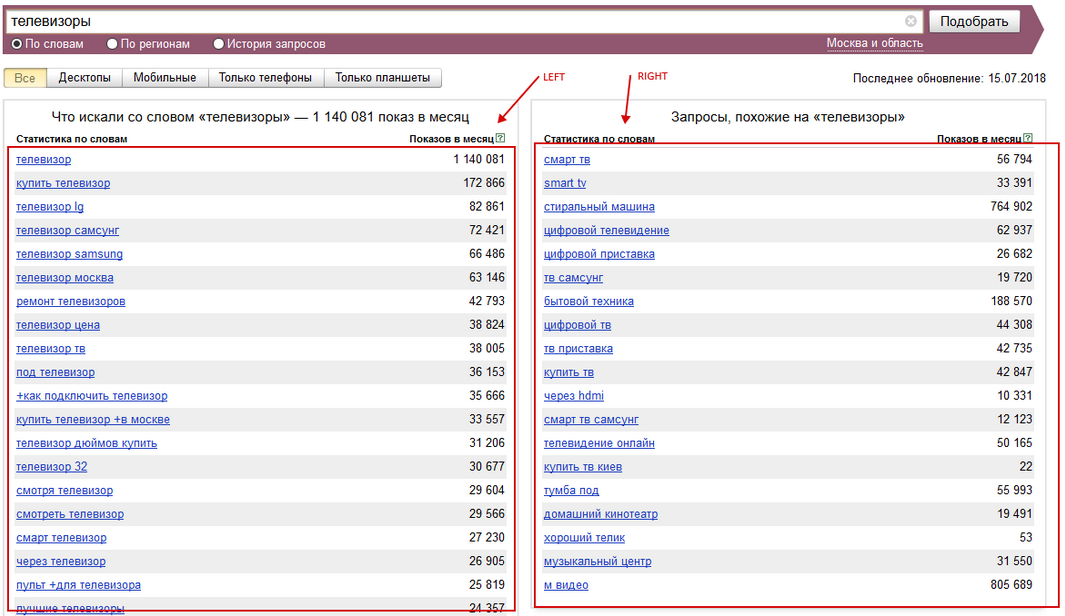
Инструмент собирает запросы из левой и правой колонок. В интерфейсе это выглядит так:
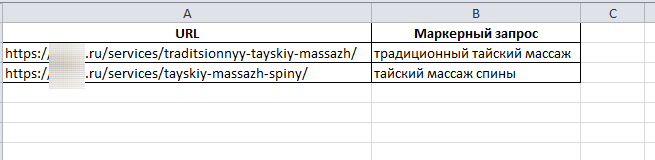
Выписываем в файл урлы страниц (документы) и напротив к ним маркерные запросы (основные запросы, которые описывают направление).
Идем в инструмент Частотность → WS - Расширение
Указываем:
— регион, например (Москва и область) #213;
— название задания;
— глубину (количество страниц вордстата, 5ти обычно достаточно);
— список маркерных запросов;
— минус фразы, если необходимо (это стоп слова, которые будут отсеиваться при сборе, например, мы точно знаем, что нам не нужны в семантике запросы, которые содержат "отзывы", "фото", "дешево". Вписываем этот список в "Минус фразы" и в выходном файле запросов с этими словами не будет).
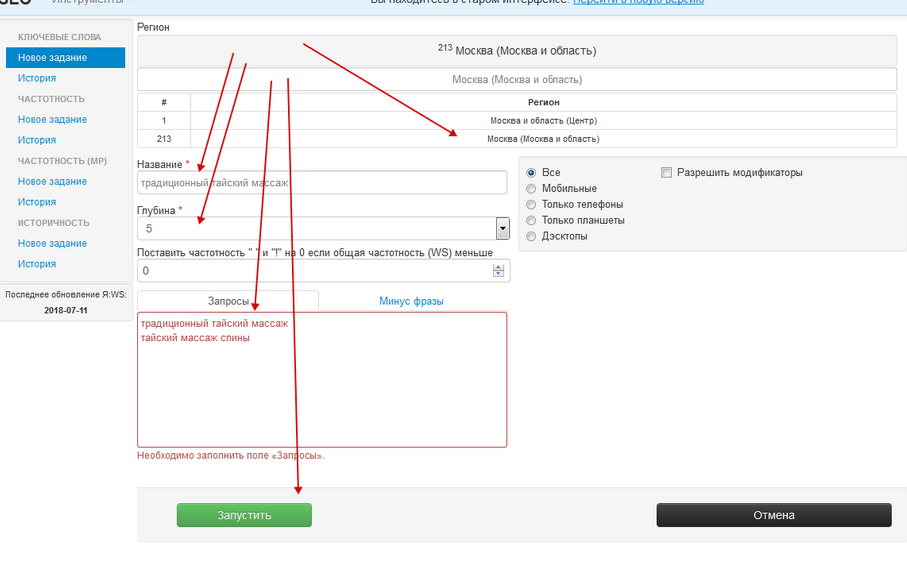
И запускаем задание.
Выгружаем собранное.
Удаляем в столбце все RIGHT (это правая колонка, ассоциативные запросы, часто неподходящие)
Удаляем ненужные запросы просмотром вручную.
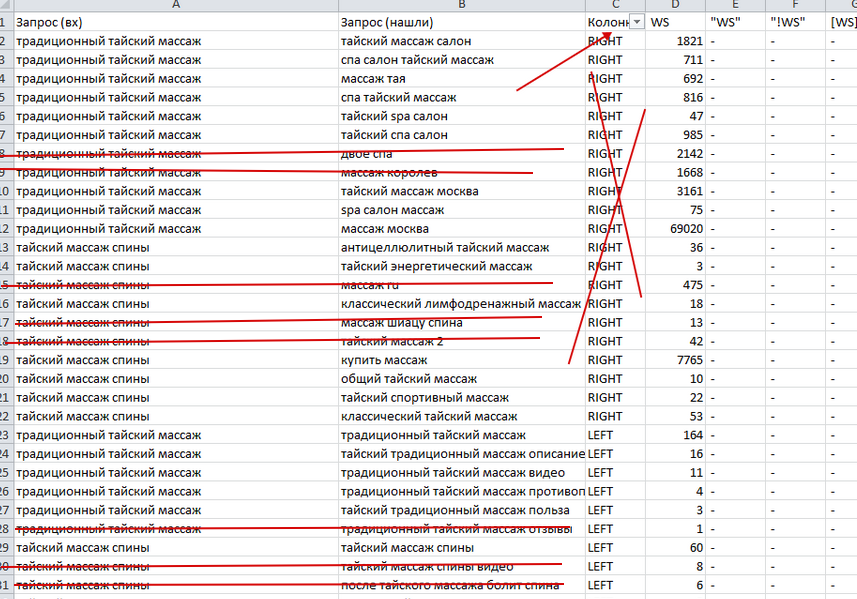
И составляем файл в формате (запрос | документ (url) | категория).
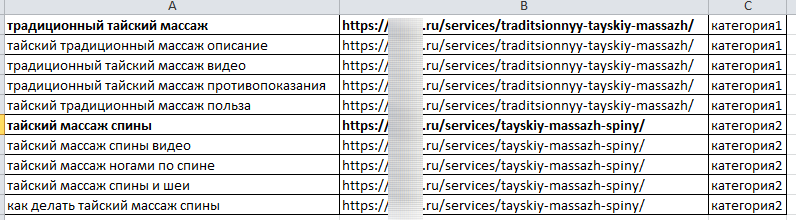
После чего запросы можно добавлять в систему. Подробнее в статье Добавление семантического ядра